A Statistical Approach To Handling Missing Data
Finding relationships between columns to reduce bias in datasets.

Samuel is a Machine Learning engineer and Python developer.
I am passionate about building sustainable and scalable models and projects that solve profound issues.
While working with various datasets, often times we have missing values in different columns. A common way of handling this is either deleting the rows that have values missing or replacing the missing value with the mean of its column. These approaches work well generally on datasets. But when you have a lot of missing values in your data, they flop.

They create noise when you have so many values repeated and you could lose a significant amount of data if you decide to drop rows with missing values.
One way to overcome this is by properly studying your data to see if there is some sort of correlation between a few or all the columns in the dataset. Taking the US Universities Data as a case study, we would walk through how we can statistically replace the missing values in a dataset.
Importing Dependencies
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
numpy - Mathematical and logical operations
matplotlib - Visualization
pandas - Data manipulation
seaborn - Visualization
Loading Dataset
us_news_columns = ['FICE (Federal ID number)', 'College name', 'State (postal code)',
'Public/private indicator (public=1, private=2)', 'Average Math SAT score',
'Average Verbal SAT score', 'Average Combined SAT score', 'Average ACT score',
'First quartile - Math SAT', 'Third quartile - Math SAT', 'First quartile - Verbal SAT',
'Third quartile - Verbal SAT', 'First quartile - ACT', 'Third quartile - ACT',
'Number of applications received', 'Number of applicants accepted', 'Number of new students enrolled',
'Pct. new students from top 10% of H.S. class', 'Pct. new students from top 25% of H.S. class',
'Number of fulltime undergraduates', 'Number of parttime undergraduates', 'In-state tuition',
'Out-of-state tuition', 'Room and board costs', 'Room costs', 'Board costs', 'Additional fees',
'Estimated book costs', 'Estimated personal spending', """Pct. of faculty with Ph.D.'s""",
'Pct. of faculty with terminal degree', 'Student/faculty ratio', 'Pct.alumni who donate',
'Instructional expenditure per student', 'Graduation rate']
us_news = pd.read_csv ('usnews.data.txt', names=us_news_columns)
us_news.head()
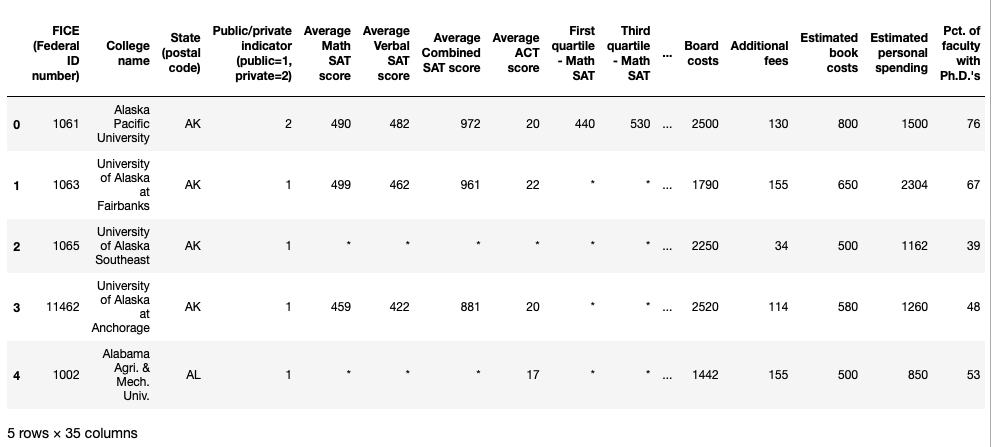
Missing Values
Missing values were represented as * in this dataset. We replace it with the NaN value and display the amount of NaN values per column.
us_news.replace('*', np.NaN, inplace=True)
us_news.isna().sum()
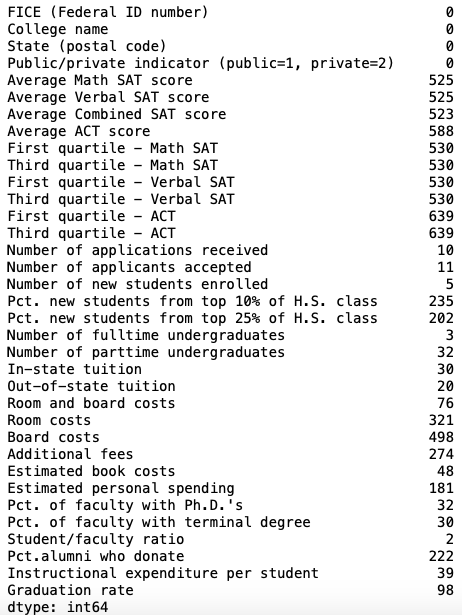
Calculating the number of rows that have at least one missing value,
>> us_news.isna().any(axis=1).sum() 1148we can observe that dropping or deleting rows that contain at least one missing value will result in a massive loss of data (1148 of 1302 points). So also will replacing the missing values with the mean of columns create a very biased dataset.
STEP 1 - ANALYSE COLUMN NAMES AND VALUES
When we take a look at the type of values we are working with, considering 'Average Math SAT score' and 'Average Verbal SAT score', we would see that the data is continuous and has a boundary (or total, 800 here). We can also see that the column 'Average Combined SAT score' has some relationship with the previous two in terms of sum.
STEP 2 - ESTABLISH RELATIONSHIPS
Check to see if there is any strong correlation between certain columns. From analyzing the column names and values, we have observed that we are dealing with standardized test scores in some parts of the dataset. Visualizing the correlation of the test scores against themselves, we see that there is a strong positive correlation (0.84 to 1) between the values of these columns. Clearly, there is a pattern they all follow.
sns.set(rc = {'figure.figsize':(12,9)})
sns.heatmap(us_news.corr().iloc[2:12, 2:12])
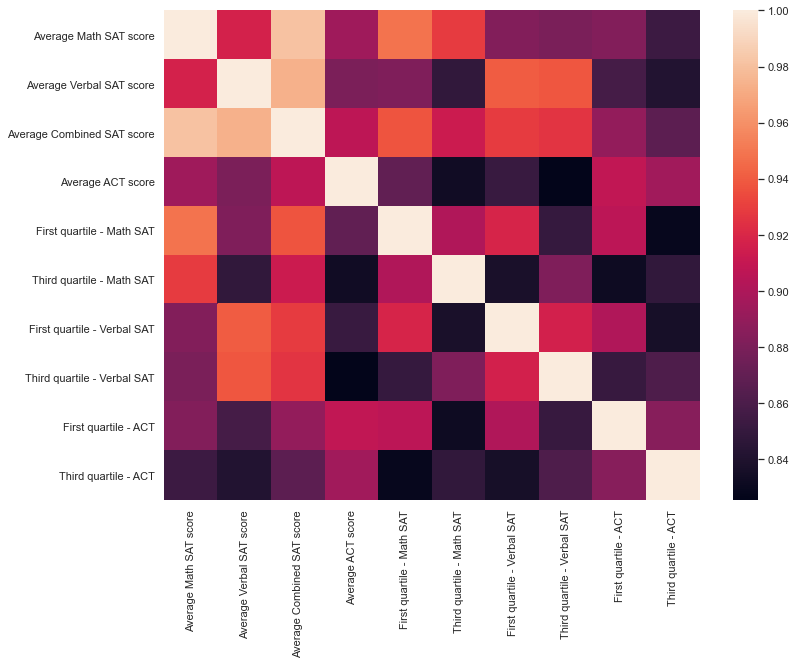
STEP 3 - REVIEW FORMULAS
Quartiles
Looking at the relationship between the first and third quartiles with average scores, these formulas connect them.
Q1 = μ – (0.6745)σ
Q3 = μ + (0.6745)σ
- Q1 represents the first quartile
- Q3 represents the third quartile
- μ represents the mean(average)
- σ represents the standard deviation(std)
Mean
In reverse to getting the quartiles with mean and standard deviation, we can also find a formula to connect the mean only to the quartile scores.
mean = (1st Quartile + 3rd Quartile)/2
I backtested this formula with sample data points and got a very minimal error.
Combination/Addition
As earlier observed while analyzing column names and values, the sum of the 'Average Math SAT score' and 'Average Verbal SAT score' give the 'Average Combined SAT score'.
Therefore the addition of the two columns would give the correct value for missing data in the third column.
STEP 4 - IMPLEMENTATION/CODE
Cleaning and Preparing Data
After checking the data types of the columns, it is observed that the majority are not in the right format.
us_news.dtypes
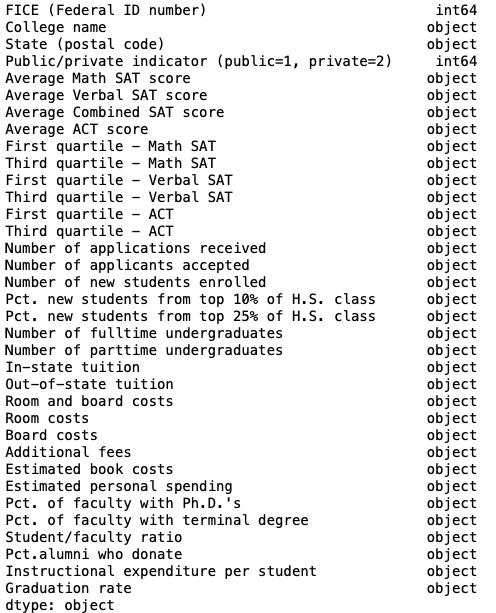 All columns from the third contain numeric data, therefore we would convert them to that format.
All columns from the third contain numeric data, therefore we would convert them to that format.
for col in us_news.dtypes[3:].index:
us_news[col] = pd.to_numeric(us_news[col])
## Defining the columns to be worked on.
average_to_check = ['Average Math SAT score', 'Average Verbal SAT score', 'Average ACT score']
quartiles = [['First quartile - Math SAT', 'Third quartile - Math SAT'], ['First quartile - Verbal SAT',
'Third quartile - Verbal SAT'], ['First quartile - ACT', 'Third quartile - ACT']]
Replacing Missing Quartiles
With the formulas established for the first and third quartiles, we loop through every column that has its quartile values missing and apply it.
for index, score in enumerate(average_to_check):
us_news.loc[(us_news[quartiles[index][0]].isna()) & (us_news[score].notna()), quartiles[index][0]] = us_news.loc[(us_news[quartiles[index][0]].isna()) & (us_news[score].notna()), score].map(lambda x: x - (.6745)*us_news[score].std())
us_news.loc[(us_news[quartiles[index][1]].isna()) & (us_news[score].notna()), quartiles[index][1]] = us_news.loc[(us_news[quartiles[index][1]].isna()) & (us_news[score].notna()), score].map(lambda x: x + (.6745)*us_news[score].std())
Line 2 gets all columns that have their first quartile values missing but the average score intact. The & condition in the code ties the two separate conditions together as one boolean.
It calculates the first quartiles using the established formula and then replaces the columns with missing first quartiles with the calculated values. The standard deviation used is that of the column of the test score being considered as the std for each school isn't provided. This has also been backtested with data points with no missing values.
Line 3 does the sample function as line 2 for missing third quartile values.
Replacing Missing Averages(Mean)
With the formula established for average, we loop through every column that has its average score values missing and apply it.
for index, quart in enumerate(quartiles):
first, third = quart
us_news.loc[(us_news[average_to_check[index]].isna()) & (us_news[first].notna() & us_news[third].notna()) , average_to_check[index]] = us_news.loc[(us_news[average_to_check[index]].isna()) & (us_news[first].notna() & us_news[third].notna()), [first,third]].apply(lambda x: (x[first] + x[third])/2, axis=1)
After getting out the column names for the first and third quartiles in line 2, we get all data points that have average score values missing but have first and third quartile values intact. It applies the formula defined for calculating the average and replaces the missing values with the calculated values.
Replacing Missing Combined Scores
We get all rows with missing 'Average Combined SAT score' and replace them with the calculated values.
math = 'Average Math SAT score'
verbal = 'Average Verbal SAT score'
combined = 'Average Combined SAT score'
us_news.loc[(us_news[combined].isna()) & (us_news[math].notna() & us_news[verbal].notna()), combined] = us_news.loc[(us_news[combined].isna()) & (us_news[math].notna() & us_news[verbal].notna()), [math,verbal]].apply(lambda x: x[math] + x[verbal], axis=1)
The math scores and verbal scores are added, then replace the columns that have the combined scores missing.
Check
After using all these formulas to replace missing values, we can now check the number of missing values we have left.
As regards the test scores, the missing values were reduced significantly.
Rounding-up Cleaning
Observing the columns again, the data points with missing test scores are completely blank with no record of any sort (average or quartiles). We can:
- Choose to replace these values with the mean of their columns.
- Train a model with a section of the dataset with no missing values to predict the average test scores which can then be used on the missing values.
- From the prediction of average test scores, the formulas already established can be used to calculate the combined scores, the first and third quartiles.
Other columns in the dataset with missing values could also be replaced with the mean of their columns or have a model trained with other data points to predict their missing values.
Thanks for reading.




